Los mejores microprocesadores bajo nuestra lupa
Los chips que gobiernan nuestros PCs no dejan de progresar. Cada vez son más rápidos y sofisticados, pero su capacidad de disipación de calor y consumo no dejan de reducirse. Buenas noticias. Echemos un vistazo a lo último de Intel y AMD.
De momento, en este artículo dedicado a los cerebros de nuestros equipos, las protagonistas siguen siendo las CPUs con arquitectura x86. Losmicroprocesadores de Intel y AMD llevan años compitiendo por ser los mejores en esta arquitectura, desde los tiempos de los primeros 80286, pasando por losPentium, los Athlon 64, los Core y los Phenom, hasta llegar al presente, con losIvy Bridge de Intel y los Fusion y Trinity de AMD.
En cualquier caso, hoy más que nunca también es necesario prestar atención a otras formas de abordar el procesamiento de las instrucciones, los datos y los programas, distintos a las habituales con x86. Una arquitectura viene definida por el conjunto de instrucciones que es capaz de descodificar, así como por las jerarquías que intervienen en las unidades de predicción de las secuencias de instrucciones, o las jerarquías de memorias caché, etcétera.
Hasta ahora, la arquitectura x86 era óptima y permitía obtener incrementos espectaculares en el rendimiento con cada nueva generación tecnológica. Pero hay dos tendencias que «pisan fuerte»: por un lado, la arquitectura ARM, que empezó con su integración generalizada en móviles y luego en tabletas, con las miras puestas en los ordenadores portátiles. Y, por otro, las arquitecturas que se centran en el paralelismo masivo, como las tarjetas gráficas de NVIDIA o AMD, o, incluso, las MIC de Intel, aunque esta última está basada en paralelismo a partir de decenas de procesadores x86 simples.

ILP y TLP
El paralelismo es clave para obtener mejoras en el rendimiento. El modelo tradicional basado en incrementos de la frecuencia de reloj junto con optimizaciones de la arquitectura ha llegado a un punto a partir del cual las mejoras en rendimiento son lentas. De hecho, la frecuencia de reloj de los microprocesadores se ha estancado en torno a los 3,5 GHz, en sus valores máximos.Un programa es una secuencia de instrucciones, de modo que lo que se ha buscado en la arquitectura x86 durante los últimos años ha sido maximizar el paralelismo a nivel de instrucciones (ILP o Instruction Level Parallelism). Es decir, descodificar varias simultáneamente en el cauce de ejecución (pipeline) del procesador al ritmo que marca la frecuencia de reloj.
Para ello integra mecanismos como las unidades de predicción, que adivinan qué instrucciones se van a ejecutar, las lee desde la memoria y las preprocesa con la esperanza de que el orden sea correcto. Las memorias caché almacenan en sus celdas superrápidas los datos que previsiblemente se vayan a usar, trayéndolos de la memoria principal antes de que se necesiten.
Por otro lado, ahora se tiende a tener varios núcleos en un mismo chip para aprovechar el paralelismo a nivel de hilos de ejecución (TLP o Thread Level Parallelism). Se depende de que el programa o el sistema operativo sepan cómo lanzar estos threads (hilos de ejecución). De todos modos, el número de núcleos en un chip, con arquitecturas x86 complejas, no puede ser (de momento) muy elevado. Las unidades de predicción, las memorias caché, etcétera, ocupan mucho silicio.
De todos modos, si el programa está pensado para procesarse en paralelo mediante el lanzamiento de cientos o miles de hilos de ejecución, esta aproximación sí tendría sentido. Es la que adoptan NVIDIA y AMD en sus tarjetas gráficas, que ahora empiezan a usarse como procesadores de propósito general o GPGPU. Estas tarjetas tienen miles de procesadores simples trabajando en paralelo, y han demostrado que para problemas susceptibles de paralelizarse se obtienen mejoras de varios órdenes de magnitud en el rendimiento, y también en el consumo de energía. Las arquitecturas masivamente paralelizadas están demostrando ser muy eficientes energéticamente.
La computación heterogénea
Paralelizar un problema a nivel de programación puede ser muy sencillo, complicado o imposible. En aplicaciones de cálculo científico, ingeniería, simulaciones, etcétera, el paralelismo es la respuesta natural para «atacar» un problema. Pero, en otros casos, el paralelismo a nivel de instrucción es suficiente para conseguir un nivel de rendimiento óptimo. Lo mejor es combinar ambos tipos de procesadores y hacer que trabajen juntos en la resolución de un problema. De hecho, ya hay procesadores por parte de AMD (Fusion) e Intel(Sandy Bridge e Ivy Bridge) que combinan paralelismo por parte de la tarjeta gráfica y procesadores x86 convencionales.El resultado es la computación heterogénea. Se aplica especialmente en súper ordenadores, aunque salvando las distancias también lo puedes encontrar en los equipos de sobremesa y en los portátiles. Este camino hacia la computación heterogénea pasa por seguir mejorando y optimizando tanto los procesadores basados en ILP como en TLP.
Estamos en un momento en el que la arquitectura de los ordenadores vuelve a estar en auge. En la parte de la arquitectura x86 convencional, la de losprocesadores AMD Phenom y los nuevos A6 o A8, o los Intel Core Sandy Bridgeo Ivy Bridge, las mayores novedades están en el campo de la eficiencia energética o en el de los gráficos integrados. Sí, ciertamente se mejora también todo lo relacionado con las unidades de predicción y se refinan los algoritmos que gestionan las cachés. Pero los movimientos más rápidos vienen de la mano del silicio a cargo del paralelismo.
AMD, Intel y su legado
De momento, AMD solo ha anunciado y presentado su nueva plataforma Trinity. Con Llano rompió un poco con todo y ofreció un procesador con un buen equilibrio entre potencia gráfica y potencia de CPU. Ahora llega Trinity, con 2 o 4 núcleos Bulldozer de segunda generación, denominados Piledriver. Sigue con la fórmula de los módulos, donde un módulo contiene dos núcleos para el cálculo de enteros y uno para coma flotante.Las mejoras están en el lado de la optimización de todo lo que tiene que ver conILP, unidades de predicción, prefetch, gestión de la caché, etcétera. Y del lado de la optimización del consumo energético. De todos modos, aún no hemos tenido en nuestro Laboratorio un producto final y tangible para poder actualizar el ranking de procesadores.
De Intel e Ivy Bridge sí que hemos hablado en su día acerca de su tecnología y novedades funcionales, donde destaca la transición a la tecnología de fabricación de 22 nm, con transistores Tri-Gate, así como la mejora del rendimiento de los gráficos integrados con más unidades de ejecución y compatibilidad con DirectX 11; mejoras en la tecnología QuickSync, aparte de optimizaciones en el apartado de la gestión de energía con hasta un 50% menos de consumo para un mismo rendimiento comparado con Sandy Bridge, o compatibilidad con PCI Express 3.0. Hay que recordar que Ivy Bridge es más un cambio en la tecnología de fabricación que en la microarquitectura.
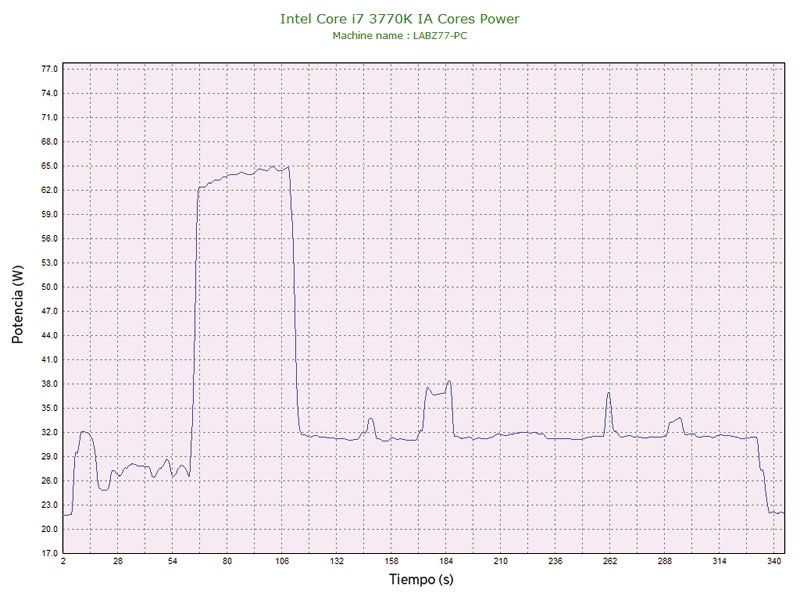
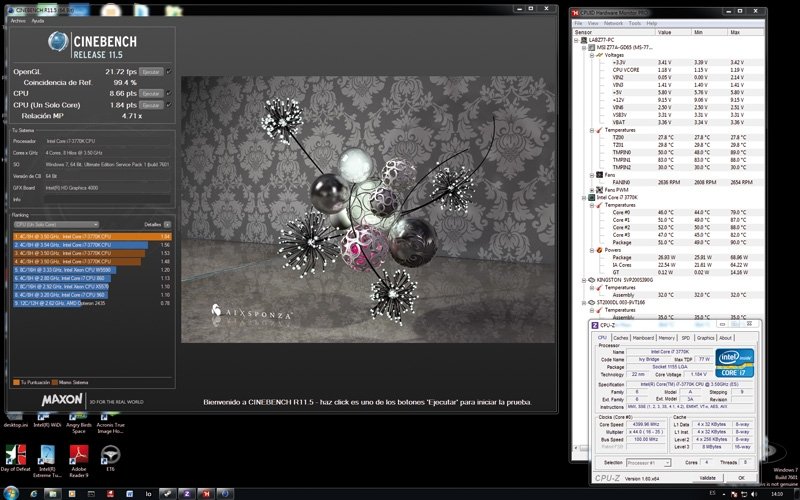
Aprovechando que existen excelentes herramientas de software que permitenauditar en tiempo real el estado de los parámetros de funcionamiento de la CPU, como HW Monitor, nos hemos embarcado en la tarea de ejecutar algunos tests habituales monitorizando las constantes vitales del equipo en segundo plano, tanto con Ivy Bridge como con Sandy Bridge.
La prueba estrella es Cinebench R11.5, con cargas de trabajo tanto para la GPU (OpenGL) como para la CPU, y para todos los núcleos como para uno solo. También hemos analizado el comportamiento con CyberLink MediaEspresso 6.5, que permite usar aceleración QuickSync y la CPU exclusivamente para la tarea de la recodificación de un vídeo.










0 comentarios:
Publicar un comentario